Увод
Настоящата работа е посветена на книгата на Васил Миков „Произход и значение на имената на нашите градове, села, реки, планини и места“. Основната ѝ цел е създаване на електронен модел за издание на данни по ономастика. В следващите страници ще се запознаете с целите и начина на работа по темата, а след това с отговори на въпросите: „Кой е Васил Миков?“ и „Какво е допринесъл за историята на българската ономастика?“. Същинската част е посветена на подробно изложение на основния фокус на този труд. Той съдържа технологична част, а именно описание на модела на електронното издание на книгата.
Ще бъдат разгледани основните състояния на компютърните езици, които са използвани за платформата и написването на електронния модел. Това са: XML, XSLT, HTML, CCS, JS, XQuery, Bootstrap и eXist database. За всеки един от тях ще бъде дадена информация за какво служи, кога и как се използва и как ни е послужил в проекта. Също така ще намерите информация за основните характеристики на всеки един език и как ни е послужила технологията. На места ще бъдат използвани схеми за улесняване и възприемане на информацията. Целта е създаване на единна електронна среда за публикуване и обработка на научната информация. Това не бе самоцел. Предложеният подход би могъл да послужи при издание на значими научни трудове и представя една линия в дигиталната хуманитаристика с приложение при направлението, свързано с опазване и популяризиране на културното наследство.
Основната цел на работата е запознаване с моделите и начините за създаване на електронното издание, като за илюстрация на този подход е избрана една от книгите на изтъкнатия археолог. Самият електронен вариант може да видите на адрес http://slav.uni-sofia.bg/proizhod. В него освен с текста от книгата, можете да се запознаете с информация за всеки един град, село, крепост, пещера, и т. н., изобщо всяка една местност, която е упомената от Васил Миков. Начинът на разработване и достигане до тази опция, а именно поставяне на мишката върху думата и препращането към съответната информация, е дело на модела, представен тук. Също така проектирахме отвеждане към конкретната локация за всеки един топоним. Друга интересна възможност от електронния модел е така наречената търсачка. Освен общото търсене в целия корпус, чрез нея могат да бъдат групирани и изваждани на показ от цялото съдържание на книгата например думи, които се характеризират с определен словообразувателен модел, напр. завършват на -ище, - ица -градъ, -ник и т.н.
Начин на работа
Текстът на книгата е взет от сайта http://macedonia. kroraina.com/vmpi/index.htm. Бе направена пълна сверка и редакция спрямо изданието от 1943 г., след което се пристъпи към трансформацията на данните в XML формат. Бяха маркирани интересуващите ни части от текста.
Бе решено да се предложат два формата – единият представя книгата в цялостен вид. Той е предназначен за традиционно четене. При другия разделихме книгата на отделните ѝ глави с цел по-бързото намиране на отделните части при търсенето.
В областта на дигиталната хуманитаристика и електронното публикуване съществуват редица модели и подходи. Затова голяма част от времето бе посветена на намиране на адекватен модел за представяне на научната информация, заложена в книгата. Избрахме моделите, прилагани от Австрийския Център за дигитална хуманитаристика. Особено подходящ ни се стори подходът прилаган при изданието на кореспондецията на Лео фон Тун-Хоенщайн (Andorfer 2017). За основа бе взето именно това приложение, като идея и софтуерни решения. Отделните топоними в книгата бяха маркирани, а след това бе съставен отделен списък, в който се въведоха данни за мястото – класификация според типа топоним, данни за географската ширина и дължина, връзки към карти и т.н.
Една от целите на тази работа е да предложи не просто електронно издание на една книга, а да се илюстрира как чрез използването на модерни технологии, стандарти и добри практики може да се осъществи приложение, почиващо на продукти с отворен код, което да послужи за модел при осъществяването на проекти в областта на дигиталната хуманитаристика и опазването на културното наследство в България.
Акцент в тази работа са именно технологичните решения в областта. Оставихме настрана въпросите за редица спорни етимологични решения на Васил Миков. Подобен коментар на този етап ни се стори излишен. При едно бъдещо развитие те биха били уместни в уводните думи към изданието или като дискусия под линия, без да се нарушава целостта на оригиналния текст.
Полезните езикови данни от книгата на В. Миков също не са били специален обект на интерес. Тяхното значение е било подчертавано неведнъж (Балабанов 1996; Герасимова 2000; Коев 2015). Един бъдещ задълбочен подход в тази насока би обогатил предлаганото в тази магистърска теза софтуерно решение.
За целите на работата ни се стори особено ценно изготвянето на списък с наименования на топоними, срещани в книгата на Васил Миков. Техният брой постепенно нарастна на повече от 1300. Това обаче далеч не са всички срещани в труда наименования. В редица случаи изпитахме трудности да решим за кой точно топоним говори Миков. Особено мъчно това се оказа за случаите, в които на едно и също название отговарят селищно име и река, наличието на селища с едни и същи наименования, които в течение на годините са си сменили името, голяма част от микротопонимите. Понякога този проблем можеше да бъде решен с помощта на списък с алтернативни названия. Така се стигна до идеята всички случаи в текста да водят към списък, чиято основна терминологична единица е съвременното име на топонима, а старите или алтернативни имена да се прилагат отделно. Консултацията с многобройни справочници (вж. Използвана литература) бе от огромна полза в това отношение. Така можеше в редица случаи да се избегнат омонимичните неуредици. При наличие на едни и същи названия се допълваше и районът или областта, в които се среща топонимът. Пълната обработка на топонимите от книгата ще продължи. Надяваме се, че демонстрираният подход ще допринесе за това и ще бъде полезен за бъдещи издания и проучвания в областта.
Сверяване със съвременните изследвания
За да се сравнят имената на населените места, споменати в книгата със съвременните им названия, бяха използвани няколко справочника: Коледаров и Мичев 1973, Мичев и Коледаров 1989, Андреев 2002, Мичев 2005.
Беше направено всичко възможно да се сравнят и проверят данните от книгата на Васил Миков с по-новите проучвания в тази област. Тук ще изброим само посочки към отделни изследвания, подредени според местата:
- Ардинско: Христов 2009
- Беленско: Ковачев 2009
- Босилеградско: Кацарова-Папа 2009
- Брезнишко: Велев 2009
- Елипелинско: Близнашка-Янева 2013
- Елховско: Мишева 2013
- Ивайловградско: Бечева 2010
- Карловско: Първанова-Грьошел 2011
- Карнобатско: Момчилов 2013
- Кулско: Заяков 2013
- Ловешко: Ковачев 2013
- Луковитско: Иванова 2009
- Малкотърновско: Райчевски 2012
- Никополско: Цанков 2010
- Пазарджишко: Балкански 2013а
- Пернишко: Велев 2010
- Плевенско: Петкова 2010
- Пловдивско: Михайлов 2010
- Родопите: Христов 2010
- Русенско: Минева-Ковачева 2010
- Сливенско: Дечев 2012
- Стара планина: Райчевски 2007
- Тополовградско: Лалчев 2010
- Тутраканско: Балкански 2011
- Харманлийско: Кокаличева 2011
- Югозападна България: Чолева-Димитрова 2002
- Ямболско: Петрова 2013
Васил Миков Вълов

Васил Миков е роден в град Ябланица (по негово време село) на 4.04.1891 г., но по-късно семейството му се премества в Бяла Слатина. Той е български археолог и праисторик. Учил е в Брюксел, както и в Софийски университет история със специалност география. Дейността му се свързва с ръководство на над 40 археологически и праисторически експедиции. Работил е като е частен доцент в Софийския университет, а по-късно в Археологическия институт при БАН. Като член на Върховния читалищен съюз е награден със специална грамота от Комитета за култура и два ордена „Кирил и Методий“. През 1966 г. става почетен член на Югославското археологическо дружество. По-известните му публикации са „Предисторически селища и находки в България„“ (1933), „Идолната пластика през новокаменната епоха в България“ (1935), „Произход и значение на имената на нашите градове, села, реки, планини и места“ (1943), „Античната гробница при Казанлък“ (1954) и др.
Атанас Коев (Коев 2015) дава по-подробна информация за Миков като пише за него статия на тема „Един от видните български археолози и праисторици“ в информационно-просветителски, аполитичен, познавателен сайт „Патриотичен десант". Електронното издание цели да запознае широката аудитория с малко известни страници от българската история, интересни личности, с културно-историческото ни наследство, непознати и красиви места в България, както и със съвети за здравето, семейството, дома и стопанството.
Васил Миков е бил мобилизиран и взима участие в Балканските войни. Работил е в Народния археологически музей като асистент на големия наш археолог Рафаил Попов, доброволен асистент по праистория в Софийския университет, назначен за ръководител на секцията по праистория в обединения Археологически институт с музей към него. Той допринася с богато научно наследство, състоящо се от над 240 научни изследвания и повече от 60 научнопопулярни статии. Успоредно с всичко това, Миков извършва и друга забележителна дейност – той успява да събере повече от 40 000 местни названия и да проучи над 10 000 лични и фамилни имена.
В книгата „Произход и значение на имената на нашите градове, села, реки, планини и места“ авторът разглежда местни названия от историческо и етнографско гледище. Съдържа: Предговор, Съкращения, Увод – общи бележки, Класификация на местните имена по групи, Литература и Показалец на имената.
В първата част Миков дава обяснение, че благодарение на работата му в музея, той е имал възможност да пропътува, както пише, „по всички посоки по-голяма част от българските земи, като според специалните ми интереси започнах да събирам и топографски имена“. Във времето Миков събира над 25 000 топонима. Класификацията на местните имена е по форма и значение, по езиков произход. Ето и какво споделя той по време на създаването на имената: "дойдох до заключение, че населението както в миналото, така и днес, независимо от неговия народностен произход, е давало поразително верни и безпогрешни наименования на местността“, като дава за пример „Гложене“, не от глог – не от растението Crateagus, а от реконструирана от него старобългарска дума със значение шумно, във връзка с шума на водите на р. Вит и на вятъра по негов тесен пролом.
В уводната част на книгата се откроява въпроса за трайността на местните имена, които съобщават кои и какви народи са живеели по нашите земи и определят етнографските им граници. По този начин сами разказват историята си, а читателят има възможността да проследи културните влияния от един народ на друг и, най-вече, топографските названия от славянски произход, а именно запазените в страната и извън нея на Балканите – в Гърция, Албания, Румъния, Тракия и Македония.
Николай Ковачев в статията си „Една обобщаваща книга по топонимията на археолога Васил Миков Вълков“ от поредицата „Състояние и проблеми на българската ономастика“ (Ковачев 1996) подчертава думите на праисторика за бъдещите и съществени задачи на топонимията ни. „Събирането на тези ценни материали трябва да се подеме по-скоро и не от един или двама, а от много, и от по-добре подготвени работници. Предстоят още много години докато се съберат всички топографски имена от всички кътове на българските земи. И едва след като се съберат всичките названия ще може да се пристъпи към тяхното тълкуване и издаване в няколко по-големи книги“ (Ковачев 1996: 318). Идеята му е добре започната и начертана, но за съжаление, все още незавършена.
Същинската част на книгата „Произход и значение на имената на нашите градове, села, реки, планини и места“ е разделена по групи: Народни тълкувания на имената; Промени в селищните и местните имена; Изчезнали и забравени имена; Преведени имена; Видоизменени и осмислени имена; Запазени названия; Пренесени имена; Тракийски имена; Илирийски имена; Имена от гръцки произход; Названия от латински и булгаро-латински; Славянски наименования; Названия от чужд произход със славянски наставки; Имена с наставки -щица; Прабългарски и печенежко-кумански имена;Турски имена; Названия с турски изговор; Албански названия; Имена, свързани с народност; Названия, свързани с обществения живот; Имена- с войни, бунтове, войници, грабежи; Също така с привилегии, правдини, задължения, данъци; Имена, свързани с лица, с понятията – жена, мома, мъж; Имена, свързани със занятия, град, крепост, кула, село, постройка, стар път, граница, както и във връзка с храмове, църкви, манастири, джамии, светии; Във връзка със самодиви, змейове, зли духове, езически вярвания; С вода, поток, извор, река, езеро, блато, мочур, безводие, бани; С изложение на мястото на слънцето – топло и студено, сянка, вятър; Имена, свързани със земеповърхни форми – пещери, пропасти, ями, вдлъбнатини; По състав на почвата – във връзка с растения, с животински мир; Във връзка с външен вид – големина, малко, високо, ниско, тясно, широко, горно, долно, средно, старо, ново; Имена, свързани с цвят; Както и във връзка с количество; – свързани с миризма и вкус; Отглаголни съществителни; Названия, свързани с различни предмети и Неопределени названия.
Класификацията му е богата и разнообразна, с цел да се обхване по-голям кръг от значения, следващи предначертана логика и изпълнени с прецизност. Книгата на Васил Миков завършва един етап от развитието на нашата ономастична наука.
В друга статия от поредицата „Състояние и проблеми на българската ономастика“ Тодор Балкански разказва за българската ономастика, като споменава, че нейната предистория започва с отделянето на проф. Й. Заимов от Секцията за общо и балканско езикознание и създаването Група за издаване на стари паметници. Основната им цел е описание топонимията на България според административното деление на околии през 1960 г. Така започва създаването на книги с тематика местните имена в различни райони. Така новосъздадената група цели продължаването на делото на Васил Миков. В заключение на статията си Тодор Балкански набляга на това, че българската ономастика означава довършване на онази част от частното българско езикознание, която в науката за останалите славянски езици може да се каже, че е на привършване (Балкански 1996). Няма национална лингвистична наука без национална ономастика.
Глава 1. Използваната технология. XML или eXtensible Markup Language

1.1. Значение
XML (eXtensible Markup Language), най-често превеждан на български като разширяем маркиращ език, е език, предназначен да изведе структурата на един документ чрез отбелязване с етикети (англ. tags), без да влага предварителна семантика при обозначаването с отделните маркери. Именно поради това той може да служи и като метаезик, т.е. език за описание на друг език. Неговите предимства можем да обобщим по следния начин.
1. Езикът следва да се употребява навсякъде където е нужна многократна употреба на една и съща или подобна структура на документите;
2. Където се изисква преносимост на съдържанието и неговото съхранение във времето;
3. Това се постига чрез стандартизация в развитието на кодиране на информацията (по Birnbaum 1995).
ХML се използва в много аспекти на съставянето и обработката на електронната информация – от електронния документ, през метаданните за данните за него, до сложните описания и каталогизация на различни обекти. Основните единици на маркиране да бъдат текст, атрибути, елементи или смес от изброените. Също така съществуват и празни елементи, които могат да имат само атрибути. Имената на елементите могат да съдържат букви, цифри, тирета, долни черти, но не и интервали.
Функциите на XML се базират на улесняване при споделянето на данни, опростяване на техния пренос, опростяване промените в платформата и наличността на данни. Важен принос на XML е, че синтаксисът (структурирането) на документите се измисля само веднъж, а специализираните маркиращи езици само дефинират семантиката, т.е. набора от маркиращи етикети и тяхното значение.
XML също улеснява разширяването или надстройването до нови операционни системи, нови приложения или нови браузъри, без да губи данни. XML данните могат да бъдат достъпни за всички видове "четящи машини" като хора, компютри, гласови машини, новинарски емисии и др.
1.2. ХМL елементи
1.2.1. Общи елементи
Използвани са схемите и упътванията на консорциума Text Encoding Initiative (TEI).
Следващите редове съдържат обяснение на отделните части от XML, приложени в магистърската теза. Най-напред документът започва с:
<?xml version="1.0" encoding="UTF-8"?>
Така се отбелязва използваната версия на XML от препоръките за езика на консорциума W3 (XML) и начина за кодиране на знаците (за формата UTF-8 вж. RFC 3629). Следва коренният (основният) елемент:
<TEI> </TEI>
Всеки един валиден TEI документ се състои от две части: teiHeader и text.
TEI е съкращение от Text Encoding Initiative, инициатива за текстово кодиране.Той съдържа един единствен документ, комбиниращ TEI заглавието с един или повече членове от модела. Именно това заглавие е задължителния елемент.
<teiHeader>
Следва елементът
<fileDesc>
което е съкращение от file description, а именно описание на файла. Функцията му е резултатът от търсенето да възпроизвежда всеки пример от файла в насоки. Той съдържа пълно библиографско описание на електронния файл. Следващият елемент е заглавното изявление или
<titleStmt>
(title statement). Този елемент дава информация за заглавието на произведението и тези, които отговарят за съдържанието му. Непосредствено го следва
<title>
а именно самото заглавие. Името му се вмъква между отварящия елемент, в случая
<title> и задължително неговия затварящ етикет, който се бележи с /, например
</title>.
Ако един елемент е отворен, но не е затворен по този начин, то програмата ще даде сигнал за грешка. Логично след него следва елементът
<author xml:id="vm">
Този елемент в библиографска справка, съдържа името (имената) на автор, личен или корпоративен, на произведение; например в същата форма като тази, предоставена от признат орган за библиографско наименование. Атрибутът задава името на автора на книгата, а именно Василъ Миковъ, което е упоменато в следващите поделементи:
<forename xmlns:tei="http://www.tei-c.org/ns/1.0" type="male">Василъ</forename>
и
<surname>Миковъ</surname>
<persName> или personal name съдържа собствено съществително име или собствена фраза, отнасяща се до лице, евентуално включващо едно или повече от имената, фамилното име, почетните имена, добавените имена и т.н. Линкът, който е поставен в елемента ни препраща към Virtual International Authority File, или Виртуален международен файл на автора, той изглежда така:
<persName key="http://viaf.org/viaf/193896348">
Следващият елемент съдържа допълнителна информация за отговорността за библиографски обект, например името на лице, институция или организация (или повече), действащи като издател, компилатор, преводач и др.
<editor xml:id="ab">
Библиографските справки обикновено включват заглавието на цитираните произведения и имената на тези, които са интелектуално отговорни за тях. За статии в списания или колекции такива изявления трябва да се появяват както на аналитичното, така и на монографичното ниво. Предлагат се следните елементи за маркиране на елементите за търсене:
<title><author>
<editor>
<respStmt>
<resp><name>
Респективно след <editor> следват:
<respStmt><resp>XML вариант от </resp><persName xml:id="cp">
<forename>Цветелиана</forename><surname>Петкова</surname></persName></respStmt>
Responsibility information или информация за отговорността съдържа информация за отговорността за интелектуалното съдържание на даден текст, издание, запис или серия, в които автор на специализирани елементи, редактор са недостатъчни или неточни; също полезни за предоставяне на информация на лица или организации, участващи в производството или разпространението на библиографски обект.
<resp>
Responsibility или в превод отговорност съдържа фраза, която описва естеството на интелектуалната отговорност на дадено лице или ролята на организацията при произвеждането или разпространението на произведение. Логично в този елемент са зададе отново елементите:
<persName><firstname><surname>
Следващият елемент publication statement или оповестяване за публикуване включва информация за публикуването или разпространението на електронен или друг текст.
<publicationStmt>
Друг важен елемент е:
<publisher>
издател, като показва името на организацията, отговорна за публикуването и разпространението на библиографски обект. Логично след това се опоменава и мястото на издаване и дата:
<pubPlace>
и
<date>
Следващият елемент предоставя информация за наличието на текст, като например ограничения за използване или разпространение, лицензиране и т.н.
<availability><licence target="https://creativecommons.org/licenses/by/4.0/" notBefore="2016-08-02">
След което се въвежда текст, чието съдържание е този лиценз. Описанието бива поставено в елемента <p>. Той отбелязва параграф в текста на прозата. Съдържанието на книгата също е поставена в такива параграфи.
Source description или описание на източниците описва източника, от който се получава електронният текст. Обикновено библиографско описание в случай на цифров текст или термин като "роден цифров" за текст, който е достъпен само в електронна форма.
<sourceDesc>
Веднага след него следват елементите
<biblStruct>
<monogr>
<author>
structured bibliographic citation или структурирана библиографска цитировка, която съдържа структурирана библиографско цитиране, в което се появяват само библиографски поделементи и то в определен ред. Мonographic level или монографично ниво съдържа библиографски елементи, описващи части на нивото на цялата книжна единица (книга, списание или сборник от статии). Следващият елемент е група или групи информация, свързана с публикуването или разпространението на библиографска единица.
<imprint>
Следват елементите encoding description, editorial practice declaration, quotation. Oписание на кодирането (encoding description) документира връзката между електронния текст и източника. Декларацията за редакционна практика (editorial practice declaration) предоставя подробности за редакционните принципи и практики по време на кодирането на текст. Цитатът (quotation) уточнява редакционната практика, приета по отношение на употребата на формалните методи на употреба на цитирането (например кавичките) в оригинала.
<encodingDesc><editorialDecl><quotation>
Text-profile description или описание на текстовия профил предоставя подробно описание на небиблиографските аспекти на текста, по-специално използваните езици и класификация на термините или ситуацията, в която са били създадени, участниците в проектите и условията за създаването на проекта.
<profileDesc>
Text classification или класификация на текст, която описва естеството или темата на текста по отношение на стандартна схема за класификация, тезаурус и т.н.
<textClass>
Keywords съдържа списък с ключови думи или фрази, а term – дума или словосъчетание, което се счита за технически термин.
<keywords>
<term>
Revision description или описание на промените обобщава историята на корекциите за даден файл.
<revisionDesc>
ListChange групира редица описания на промените, свързани с създаването на изходен текст или ревизия на кодиран текст. A Change e описание на промяната, направена по време на изготвянето на документа или по време на преразглеждането и редакцията на електронно досие.
<listChange>
<change>
Text съдържа текст от всякакъв вид, независимо дали е единичен или композитен, например поема или драма, колекция от есета, роман, речник или проба от корпус.
<text>
Front е предназначен да представи материал, който е в началото на електронния документ (заглавки, резюмета, заглавна страница, предговори, посвещения и др.), преди главното тяло.
<front>
Title page съдържа заглавната страница на текст, който се появява в предната или в задната част.
<titlePage>
Document title съдържа заглавието на документ, включително всички негови съставни части, както е посочено на заглавната страница.
<docTitle>
TitlePart съдържа подраздел или подразделение на заглавието на произведението, както е посочено на заглавната страница.
<titlePart>
Byline съдържа основната декларация за отговорност, дадена за работа на заглавната страница или в началото или в края на произведението.
<byline>
Document author съдържа името на автора на документа, както е посочено на заглавната страница (често, но не винаги, съдържаща се в библиотеката).
<docAuthor>
Document imprint съдържа израза за отпечатване (място и дата на публикуване, име на издателя), както е дадено (обикновено) в подножието на заглавната страница.
<docImprint>
Name съдържа име, в случая на издателя и печатницата.
<name>
Document date съдържа датата на документа, посочен на заглавна страница или в дати.
<docDate>
Epigraph съдържа котировка, анонимна или присвоена, която се появява в началото или в края на секция или на заглавна страница.
<epigraph>
Body съдържа цялото тяло на един единствен текст, с изключение на всяка предна или задна част.
<body>
Page break е предназначено да обозначи границите на страницата – нейното начало, съответно край на предишната.
<pb/>
Heading съдържа всякакъв вид заглавка, например заглавието на раздел или заглавието на списък, речник, описание на ръкопис.
<head>
1.2.1. Елементи за индексиране на лица и места
Файловете, служещи за индексиране на лица, места почиват на малко по-различна структура. При индекса на местата специфичният ред е следният:
<div type="index_places">
<listPlace><place xml:id="place_Brod_Novaci" type="oikonym">
<placeName type="pref">Брод</placeName>
<placeName type="alt">Бродъ</placeName>
<region>Новаци, Мак.</region>
<location><geo decls="#LatLng">40.95115 21.56498</geo></location>
<idno></idno>
<note></note>
</place>
<place xml:id="place_Brod" type="oikonym">
<placeName type="pref">Брод</placeName>
<placeName type="alt">Бродъ</placeName>
<region>Хс.</region>
<location><geo decls="#LatLng">42.03333 25.68333</geo></location><idno></idno>
<note><ref target="">Допълнителна информация</ref></note></place></listPlace></div>
При лицата това изглежда така:
<person xml:id="arnaudov-mihail">
<persName><surname>Арнаудов</surname><forename>Михаил</forename></persName>
<note><p>Русе 1878–1978 София</p>
<p>Акад. Арнаудов е автор на повече от 50 монографии, посветени на Паисий Хилендарски, Неофит Бозвели, Васил Априлов, Иван Селимински, Георги Раковски, Любен Каравелов, Тодор Влайков и др. Изследва творчеството на класиците на българската литература — Иван Вазов, Пейо Яворов, Кирил Христов, Йордан Йовков, Димчо Дебелянов и други.</p><p>
< target="http://unicat.nalis.bg/Author/Home?author=Арнаудов">http://unicat.nalis.bg/Author/Home?author=Арнаудов"Арнаудов</ref>, Михаил Петров 1878-1978</p></note></person>
Division съдържа подразделение на предната страна, тялото или гърба на текста.
<div>
List of places съдържа списък с места, по избор последван от списък с връзки (различни от ограничен), определени между тях.
<listPlace>
Place съдържа данни за географско местоположение.
<place>
PlaceName дава данни за абсолютно или относително име на мястото. В базата от данни се използва два или повече пъти в случай, че е посочена стара форма на съответната сегашна дума на място, или нейното гръцко, албанско, турско или латинско наименование.
<placeName>
Region съдържа името на административна единица като държава, провинция или окръг, по-голяма от населено място, но по-малка от държава.
<region>
Location определя местоположението на дадено място като набор от географски координати, по отношение на други наименовани геополитически единици или като адрес.
<location>
Identifier предоставя всякаква форма на идентификатор, използвана за идентифициране на някакъв обект, като например библиографска единица, лице, заглавие, организация и др. по стандартизиран начин.
<idno>
Note съдържа бележка или анотация.
<note>
Reference дефинира препратка към друго местоположение, евентуално модифицирано с допълнителен текст или коментар. В случая е препратка към информация за конкретното място.
<ref>
Geographical coordinates съдържа израз на набор от географски координати, представляващ точка, линия или област на повърхността на Земята в някои нотации.
<geo>
Глава 2. XSLT или eXtensible Stylesheet Language for Transformations
2.1. Значение
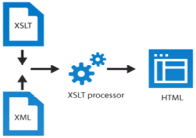
XSLT (eXtensible Stylesheet Language for Transformations) или разширяем стилов език за транформации е стилистичен език за XML.
XSLT се използва за широк спектър от задачи за трансформация. Езикът описва правила за трансформиране на входните данни в изходни данни. Входовете и изходите ще бъдат копия на модела за данни XDM (вж. XDM). В най-простия и най-често срещания случай входът е XML документ, наречен дърво на източника, а изходът е XML документ, наречен дърво на резултатите. Възможно е също така да се обработват множество изходни документи, да се генерират няколко резултатни документи и да се обработват формати, различни от XML. Трансформацията се постига чрез набор от шаблонни правила. Правило е, че когато шаблон свързва шаблон, той обикновено съвпада с възлите (nodes) в изходния документ, с конструктор на последователност. В много случаи оценяването на конструктора на последователности ще доведе до конструирането на нови възли, които могат да бъдат използвани за произвеждане на част от дървото с резултати. Структурата на резултатните дървета може да бъде напълно различна от структурата на дърветата-източници. При конструирането на дървото на резултатите възлите от източниците могат да бъдат филтрирани и пренаредени и да могат да се добавят произволна структура. Този механизъм позволява да се използва стилова таблица за широк клас документи.
Езикът XSLT има статут на препоръка на консорциума W3. Към този момент версията е XSLT 3.0 (вж. XSLT).
Стиловете обикновено включват елементи, дефинирани от XSLT, както и елементи, които не са дефинирани от XSLT. Елементите, дефинирани от XSLT, се отличават с използването на пространството за имена, което в тази спецификация е посочено като пространство за имена на XSLT. По този начин тази спецификация е определение на синтаксиса и семантиката на пространството на имената на XSLT.
На схемата по-долу можете да видите кратък преглед на XSLT и XPath, както и обяснение разликата между XPath, XSLT, XQuery и XSL-FO. XSLT може да бъде използван за трансформиране на документи в XSL-FO за печат или разглеждане, както и като общ език за програмиране и преобразуване на XML. XSL-FO може бъде използван директно без XSLT. Типично приложение е XML документи в PDF.
XSLT означава XSL трансформации. XSLT 2.0, XPath 2.0 и XQuery 1.0, споделят същата библиотека с функции. Има над 100 вградени функции. Има функции за низови стойности, цифрови стойности, сравнение на дата и час, манипулация на възел и QName, манипулиране на последователности и др.
XSL Transformations (XSLT 3.0) е език за трансформиране на XML документи в други XML документи, текстови документи или HTML документи. Може да искате да форматирате глава от книга, като използвате XSL-FO или може да искате да направите заявка за база данни и да я форматирате като HTML.
С XSLT 3.0 процесорите могат да работят не само на XML, но и на всичко, което може да се направи като XML:
- таблици на релационни бази данни;
- географски информационни системи;
- файлови системи;
всичко, от което XSLT процесорът може да изгради инстанция на XDM. В някои случаи XSLT може да работи директно от база данни с XDM потребителски модели. Тази способност да се работи на множество входни файлове в множество формати и да се третира като XML файлове е много мощна.
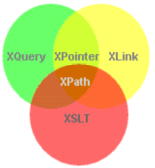
XSLT се споделя с XQuery и с цялото семейство на XML, използвайки XPath 2.0
XPath е прост език за идентифициране на части от XML документ. Използва се от XSLT, а също и от XLink, XInclude, XQuery. XPath не може да се използва самостоятелно: той винаги е част от структурата на документа и от неговата схема, независимо дали този език е XML, XSLT или някой друг. XPath може да бъде много мощен.
2.2. Скриптове
В тази дипломна работа се използват скриптове. Те биват няколко XSLT скрипта:
- Скрипт за транформиране към HTML на изворовия материал – XmltoHTML.xsl
- Скрипт за издаване на магистърската теза – meta.xsl
- Скрипт за изобразяване на информацията на местата – listplace.xsl
- Скрипт за изобразяване на информацията за лицата – listperson.xsl
Първите два скрипта са почти еднакви с изключение на това, че при първия е обособена част за метаданни и част за самото издание на извора.
Третият и четвъртият скрипт служат да се визуализира допълнителната информация за местата и лицата при приближаването на мишката към съответния термин.
Тук ще приведем някои специфични части от четирите файла с кратки обяснения.
При първите два файла се използва класическата подредба като отначало са частите за общото структуриране на уеб страницата, а след това следват скриптове за oтделните нейни части.
Листовият стил на XSL се състои от един или повече правила, които се наричат шаблони (templates). Te съдържат указания, които да се прилагат, когато определен възел (node) е съвпадащ.
Елементът <xsl: template> се използва за създаване на тези шаблони.
Атрибутът match се използва за свързване на шаблон с елемент на XML. Той може да се използва и за дефиниране на шаблон за целия XML документ. Стойността на атрибута за съвпадение е израз на XPath (т.е. match= "/" дефинира целия документ).
<xsl:template match="/">
Classes указва всички класове, в които документният елемент или клас е член или подклас. Тук се използват класовете на библиотеката Bootstrap.
<div class="page-header">
Елементът <h> се използва за уточняване на текст (обосновка) на заглавните елементи. <h2 align="center"> буквално означава заглавие на HTML подравнено по средата. Атрибутът "align" указва хоризонталното подравняване на заглавието.
<h2 align="center">
Елементът <xsl: for each> ви позволява да направите примка в XSLT.
<xsl:for-each select="//tei:fileDesc/tei:titleStmt/tei:title">
Елементът <xsl: apply-templates> прилага шаблон към текущия елемент или към възли на текущия елемент. Ако добавим избрания атрибут към елемента <xsl: apply-templates>, той ще обработва само поделемента (child element), който съответства на стойността на атрибута. Можем да използваме атрибута select, за да определим реда, по който се обработват възлите на поделемента, както се използва няколко реда по-надолу.
<xsl:apply-templates/>
Елементът <br/> създава прекъсване на реда в текста (carriage-return). Това е полезно за написването на стихотворение или адрес, където разделянето на линиите е значително.
<br/></xsl:for-each></h2></div>
<div class="regest"><div class="panel panel-default">
<div class="panel-heading"><h3 class="panel-title">
<h2 align="center">За документа</h2></h3></div>
<div class="panel-body">
Table съдържа текст, показан в табличен вид, в редове и колони.
<table class="table table-striped"><tbody>
Маркерът <tr> дефинира ред в HTML таблица. Елементът <tr> съдържа един или повече елемента <th> или <td>.
<tr>
Маркерът <th> дефинира клетка на заглавката в HTML таблица. HTML таблицата има два вида клетки:
Заглавни клетки – съдържат информация за заглавката (създадена с <th> елемента).
Стандартни клетки – съдържат данни (създадени с елемента <td>).
Текстът в <th> елементите е удебелен и центриран по подразбиране. Текстът в елементите <td> е регулярен и вляво подравнен по подразбиране.
<th><abbr title="tei:titleStmt/tei:title">Документ</abbr></th><td>
Можем също така да филтрираме изхода от XML файла, като добавим критерий към атрибута select в елемента <xsl: for-each>.
<xsl: за всеки изберете = "файл/ ../...">
Официалните оператори на филтри са:
= (equal)
!= (not equal)
< less than
> greater than
или
= (равно)
! = (не е равно)
< по-малко от
> по-голямо от
<xsl:for-each select="//tei:fileDesc/tei:titleStmt/tei:title"><xsl:apply-templates/>
Маркерът вмъква прекъсване на един ред. <br/> е празен, което означава, че няма краен маркер. Неговата единствена функция е да прекъсне реда.
<br/></xsl:for-each></td></tr>
<xsl:if test="//tei:msIdentifier"><tr><td>
<xsl:for-each select="//tei:msIdentifier/child::*">
Маркерът <abbr> дефинира съкращение или акроним, като "Mr.". Абревиатурата и акронимът са кратки версии на нещо друго. Двете често се представят като поредица от букви. Маркирането на съкращения може да даде полезна информация за браузърите, системите за превод и търсачките.
<abbr><xsl:attribute name="title">
Елементът <xsl: value-of> се използва за извличане на стойността на избрания възел. Атрибутът select съдържа израз на XPath, който работи като навигация в файлова система. Предната наклонена черта (/) избира поддиректории.
<xsl:value-of select="name()"/></xsl:attribute>
<xsl:value-of select="."/></abbr>
<br/></xsl:for-each></td></tr></xsl:if>
<tr><th>Ключови думи</th><td>
Маркерът <ul> дефинира неорганизиран списък. Препоръчително е да се използва елементът <ul> заедно с маркера <li>, за да се създадат неподредени списъци.
<ul><xsl:for-each select="//tei:term">
Маркерът <li> дефинира елемент от списъка. Той се използва в подредени списъци (<ol>), неорганизирани списъци (<ul>) и в списъци с менюта (<menu>). Маркерът <li> също така поддържа глобалните атрибути в HTML.
<li>
HTML връзките се дефинират с маркера <a>. Адресът на връзката е посочен в атрибута href.
<a><xsl:attribute name="href"><xsl:value-of select="concat('hits.html?searchkey=', .)"/></xsl:attribute>
<xsl:attribute name="title"><xsl:value-of select="concat('Други документи с тези ключови думи: ', .)"/></xsl:attribute>
<xsl:value-of select="."/></a></li></xsl:for-each></ul></td></tr>
Елементът <xsl:if> се използва за поставяне на условен тест спрямо съдържанието на XML файла. За да се постави условен тест (test) срещу съдържанието на XML файла, трябва да се добави елемент <xsl:if> към документ XSL.
<xsl:if test="//tei:supportDesc/tei:extent">
<tr><th><abbr title="//tei:supportDesc/tei:extent">Extent</abbr></th><td>
<xsl:apply-templates select="//tei:supportDesc/tei:extent"/></td></tr></xsl:if>
<xsl:if test="//tei:titleStmt/tei:respStmt"><tr><th>
<abbr title="//tei:titleStmt/tei:respStmt">Редактор:</abbr></th><td>
<xsl:for-each select="//tei:titleStmt/tei:respStmt">
<p><xsl:apply-templates/></p></xsl:for-each></td></tr></xsl:if>
<tr><th><abbr title="//tei:availability//tei:p[1]">Авторски права</abbr>
</th>
<td align="center">
Атрибутът href предоставя информация за адрес за връзки (посочва URL адреса за връзка).
<a href="https://creativecommons.org/licenses/by-sa/4.0/" class="navlink" target="_blank">
Атрибутът alt определя алтернативен текст, който трябва да се използва, когато не може да се покаже изображение. Стойността на атрибута може да бъде прочетена от екранните четци. По този начин, някой "слуша" уеб страницата, напр. сляп човек, може да "чуе" елемента.
<img src="../resources/img/by-sa.png" alt="eXist-db" width="10%"/>
</a></td></tr></tbody></table</div></div></div>
<div class="panel panel-default"><div class="panel-heading">
<h3 class="panel-title"><h2 align="center">Издание</h2></h3></div>
<div class="panel-body">
Елементът <xsl: choose> се използва заедно с <xsl:when> и <xsl:otherwise>, за да изрази множество условни тестове.
<xsl:choose>
Елементът <xsl:when> се използва за определяне на действие за елемента <xsl:choose>. Елементът <xsl:when> оценява израз и ако се върне вярно, се изпълнява действие. Използва се заедно с <xsl:choose> и <xsl:otherwise>, за да изрази множество условни тестове.
<xsl:when test="//tei:front"><xsl:apply-templates select="//tei:titlePage"/><xsl:element name="hr"/></xsl:when>
Оtherwise определя действие по подразбиране за елемента <xsl:choose>. Това действие ще се осъществи, когато не се прилага нито една от условията <xsl: when>.
<xsl:otherwise>
<h3><xsl:apply-templates select="//tei:div[@type = 'titlePage']"/></h3>
</xsl:otherwise></xsl:choose>
<xsl:element name="ul"><xsl:for-each select="//tei:body//tei:head"><xsl:element name="li">
<xsl:element name="a"><xsl:attribute name="href">
<xsl:text>#text_</xsl:text><xsl:value-of select="."/></xsl:attribute>
<xsl:attribute name="id"><xsl:text>nav_</xsl:text><xsl:value-of select="."/>
</xsl:attribute><xsl:value-of select="."/></xsl:element>
</xsl:element></xsl:for-each></xsl:element>
<p><xsl:choose><xsl:when test="//tei:div[@type = 'text']">
<xsl:apply-templates select="//tei:div[@type = 'text']"/></xsl:when>
<xsl:when test="//tei:div[@type = 'transcript']">
<xsl:apply-templates select="//tei:div[@type = 'transcript']"/></xsl:when><xsl:otherwise>
<xsl:apply-templates select="//tei:body"/></xsl:otherwise></xsl:choose></p></div>
<div class="panel-footer"><p style="text-align:center;">
<xsl:for-each select="tei:TEI/tei:text/tei:body//tei:note">
<div class="footnotes"><xsl:element name="a">
<xsl:attribute name="name"><xsl:text>fn</xsl:text>
Елементът <xsl:number> се използва за определяне на цялостната позиция на текущия възел в източника. Той се използва и за форматиране на номер.
<xsl:number level="any" format="1" count="tei:note"/></xsl:attribute>
<a><xsl:attribute name="href"><xsl:text>#fna_</xsl:text><xsl:number level="any" format="1" count="tei:note"/></xsl:attribute>
<span style="font-size:7pt;vertical-align:super;"><xsl:number level="any" format="1" count="tei:note"/>
Маркерът <span> се използва за групиране на вградени елементи в документ. Той не осигурява никаква визуална промяна сама по себе си. Предоставя начин да закачите част от текст или част от документ.
</span></a></xsl:element><xsl:apply-templates/></div></xsl:for-each>
</p></div></div></xsl:template>
2.3. Други XSLT файлове
Ще дадем някои примери и от другите XSLT файлове:
При обработката на имената на местата бе важно да се визуализира част от информацията при четенето на книгата. За тази цел си послужих с т. нар. модални прозорци. Идеята беше при четенето на текста да може да се види допълнителна информация: алтернативни имена на местата, GPS координати, линк към повече информация и възможност за търсене на името на мястото от самия текст.
<xsl:param name="entiyID"/><xsl:template match="/"><div class="modal" id="myModal" role="dialog">
<div class="modal-dialog"><div class="modal-content"><div class="modal-header">
Маркерът <button> дефинира бутон, върху който може да се кликне. В него може да се постави съдържание, като текст или изображения. Това е разликата между този елемент и бутоните, създадени с елемента <input>.
<button type="button" class="close" data-dismiss="modal"><span class="fa fa-times"/></button>
<h4 class="modal-title"><xsl:value-of select="//tei:place[@xml:id=$entiyID]/tei:placeName[1]"/></h4></div>
<div class="modal-body"><table class="table table-boardered table-hover"><tr><th>Други имена</th><td>
<xsl:for-each select="//tei:place[@xml:id=$entiyID]//tei:placeName">
<li><xsl:value-of select="."/></li></xsl:for-each></td></tr>
<xsl:choose><xsl:when test=".//tei:place[@xml:id=$entiyID]//tei:location"><tr><th>GPS-Координати
</th><td><xsl:value-of select=".//tei:place[@xml:id=$entiyID]//tei:location"/></td></tr>
<tr><th>ID на данните</th><td><a><xsl:attribute name="href">
<xsl:value-of select=".//tei:place[@xml:id=$entiyID]//tei:idno/text()"/>
</xsl:attribute><xsl:attribute name="target">_blank</xsl:attribute>
<xsl:value-of select=".//tei:place[@xml:id=$entiyID]//tei:idno"/></a></td></tr>
<tr><th>Споменат в други документи</th><td><a><xsl:attribute name="href">
<xsl:value-of select="concat('hits.html?searchkey=', $entiyID)"/></xsl:attribute>
<xsl:attribute name="target">_blank</xsl:attribute>натиснете тук</a></td></tr>
</xsl:when></xsl:choose></table></div>
<div class="modal-footer"><button type="button" class="btn btn-default" data-dismiss="modal">Затваряне</button>
</div></div></div></div>
Script се използва за дефиниране на скрипт от страна на клиента (JavaScript).
Елементът <script> или съдържа изявления за скриптове, или посочва външен скрипт чрез атрибута src.
Обичайните начини на използване на JavaScript са манипулиране на изображения, валидиране на формуляри и динамични промени в съдържанието.
<script type="text/javascript">
$(window).load(function(){
$('#myModal').modal('show');
});
</script>
</xsl:template>
XML е универсален маркиращ език, способен да маркира информационното съдържание на различни източници на данни, включително структурирани и полуструктурирани документи, релационни бази данни и хранилища на обекти. Езикът, който използва интелигентно структурата на XML, може да изразява заявки във всички тези видове данни, независимо дали са физически съхранени в XML или се разглеждат като XML чрез мидълуер. Xquery спецификацията описва език за заявки, търсене и извличане на данни, проектиран да бъде широко приложим за всички видове маркиращи компютърни езици.
JSON е лек формат за обмен на данни, който се използва широко за обмен на данни в мрежата и за съхраняване на данни в бази данни. Много приложения използват JSON заедно с XML и HTML. XQuery 3.1 разширява XQuery, за да поддържа JSON, както и XML, добавяйки карти и масиви към модела за данни и поддържайки ги с нови изрази в езика и новите функции в [XQuery и XPath Functions and Operators 3.1]. Списък с промените, направени след XQuery 3.1, може да бъде намерен в Change Log.
XQuery е предназначен да бъде език, в който заявките са кратки и лесно разбираеми. Също така е достатъчно гъвкав, за да потърси широк спектър от XML източници на информация, включително бази данни и документи. Работната група за заявки определя едно изискване както за синтаксиса на заявки извън XML, така и за синтаксиса на заявката въз основа на XML. XQuery се получава от XML заявка, наречена Quilt (Quilt), която от своя страна заимства функции от няколко други езици, включително XPath 1.0 (XPath), XQL (XQL), XML-QL (XML-QL), SQL (SQL) и OQL (ODMG).
XQuery 3.1 е разширение на XPath 3.1. По принцип всеки израз, който е синтактично валиден и се изпълнява успешно както в XPath 3.1, така и в XQuery 3.1, ще връща същия резултат и на двата езика. Има няколко изключения от това правило:
Тъй като XQuery разширява предварително зададените референтни единици и препратки към знаци, а XPath не го прави, изразите, съдържащи тези данни, произвеждат различни резултати в двата езика. Например стойността на обекта (entity) "&" е & в XQuery и & в XPath. (XPath често е вграден в други езици, които могат да разширят предварително зададените референтни единици или знаци, преди да бъде оценен изразът XPath.)
Ако режимът на съвместимост XPath 1.0 е активиран, XPath се държи по различен начин от XQuery по много начини, които са обсъдени в XPath.
Граматиката на XQuery 3.1 използва същата проста удължена нотация на разширената форма на Бейкъс-Наур (Extended Backus-Naur Form, EBNF) като XML със следните минимални разлики:
Всички назовани символи имат име, което започва с главна буква.
Той добавя обозначение за позоваване на продукции в външни спецификации.
Коментарите или извънграматичните ограничения върху граматическите продукции са между символите "/ *" и "* /".
Глава 3. XQuery
3.1. Значение
XML е универсален маркиращ език, способен да маркира информационното съдържание на различни източници на данни, включително структурирани и полуструктурирани документи, релационни бази данни и хранилища на обекти. Езикът, който използва интелигентно структурата на XML, може да изразява заявки във всички тези видове данни, независимо дали са физически съхранени в XML или се разглеждат като XML чрез мидълуер. Xquery спецификацията описва език за заявки, търсене и извличане на данни, проектиран да бъде широко приложим за всички видове маркиращи компютърни езици.
JSON е лек формат за обмен на данни, който се използва широко за обмен на данни в мрежата и за съхраняване на данни в бази данни. Много приложения използват JSON заедно с XML и HTML. XQuery 3.1 разширява XQuery, за да поддържа JSON, както и XML, добавяйки карти и масиви към модела за данни и поддържайки ги с нови изрази в езика и новите функции в [XQuery и XPath Functions and Operators 3.1]. Списък с промените, направени след XQuery 3.1, може да бъде намерен в Change Log.
XQuery е предназначен да бъде език, в който заявките са кратки и лесно разбираеми. Също така е достатъчно гъвкав, за да потърси широк спектър от XML източници на информация, включително бази данни и документи. Работната група за заявки определя едно изискване както за синтаксиса на заявки извън XML, така и за синтаксиса на заявката въз основа на XML. XQuery се получава от XML заявка, наречена Quilt (Quilt), която от своя страна заимства функции от няколко други езици, включително XPath 1.0 (XPath), XQL (XQL), XML-QL (XML-QL), SQL (SQL) и OQL (ODMG).
XQuery 3.1 е разширение на XPath 3.1. По принцип всеки израз, който е синтактично валиден и се изпълнява успешно както в XPath 3.1, така и в XQuery 3.1, ще връща същия резултат и на двата езика. Има няколко изключения от това правило:
Тъй като XQuery разширява предварително зададените референтни единици и препратки към знаци, а XPath не го прави, изразите, съдържащи тези данни, произвеждат различни резултати в двата езика. Например стойността на обекта (entity) "&" е & в XQuery и & в XPath. (XPath често е вграден в други езици, които могат да разширят предварително зададените референтни единици или знаци, преди да бъде оценен изразът XPath.)
Ако режимът на съвместимост XPath 1.0 е активиран, XPath се държи по различен начин от XQuery по много начини, които са обсъдени в XPath.
Граматиката на XQuery 3.1 използва същата проста удължена нотация на разширената форма на Бейкъс-Наур (Extended Backus-Naur Form, EBNF) като XML със следните минимални разлики:
Всички назовани символи имат име, което започва с главна буква.
Той добавя обозначение за позоваване на продукции в външни спецификации.
Коментарите или извънграматичните ограничения върху граматическите продукции са между символите "/ *" и "* /".
Глава 4. HTML и CSS
4.1. Значение
HTML (Hypertext Markup Language) и CSS (Cascading Style Sheets) са две от технологиите за изграждане на уеб страници. HTML предоставя структурата на страницата и нейното съдържание, а CSS е отговорен за нейното визуално оформление при различни устройства. Наред с графиките и скриптовете HTML и CSS са основата за изграждането на уеб страници и уеб приложения. HTML е езикът за описание на структурата на уеб страниците. Това е езикът, койтодава на авторите средства за:
- Публикуване на онлайн документи с заглавия, текст, таблици, списъци, снимки и др.
- Изтегляне на онлайн информация чрез хипертекстови връзки, с едно натискане на бутон.
- Дизайн форми за извършване на транзакции с отдалечени услуги, за използване при търсене на информация, правене на резервации, поръчване на продукти и др.
- Включване в документите списъци, видеоклипове, звукови клипове и други приложения.
С HTML авторите описват структурата на страниците чрез маркиране. Елементите на езиковия етикет съдържат съдържание като "параграф", "списък", "таблица" и т.н.
XHTML е вариант на HTML, който използва синтаксиса на XML, Extensible Markup Language. XHTML има всички същите елементи (за параграфи и т.н.) като HTML вариант, но синтаксисът е малко по-различен. Тъй като XHTML е XML приложение, можете да използвате други XML инструменти с него (като например XSLT, език за трансформиране на XML съдържание).
CSS е езикът за форматирането и представянето на уеб страници, включително цветове, позиции на структурните единици и шрифтове. Той позволява да се адаптира презентацията към различни видове устройства, като големи или малки или принтери. CSS е независим от HTML и може да се използва с всеки маркиращ език. Разделянето на HTML от CSS, т.е. отделянето на съдържанието от неговото представяне,улеснява поддържането на сайтове, споделянето на стилове между страниците и приспособяването на информацията към различни среди. Това се нарича разделение на структурата (или: съдържанието). CSS описва как HTML елементите трябва да се показват на екрана, хартията или на други носители. Той може да контролира оформлението на множество уеб страници наведнъж. Външните шаблони за стилове се съхраняват в CSS файлове. Идеята е, че тези файлове могат да променят външния вид на цял уебсайт само чрез една инструкция, съхранявана на едно място.
Защо
CSS
е толкова полезен?
Идеята за HTML никога не е била да съдържа елементи за форматиране на уеб страница!
HTML е създаден, за да опише съдържанието на дадена уеб страница, като например:
<h1>Това е заглавие</ h1>
<p> Това е параграф.</ p>
Когато към спецификацията на HTML 3.2 са добавени маркери като <font> и атрибути за цвят, отделните браузъри започват да ги поддържат по различен начин и тогава се превръща в кошмар за уеб програмистите. Разработването на големи уеб сайтове става дълъг и скъп процес.
За да разреши този проблем, Консорциумът на World Wide Web (W3C) създава CSS. Този езикпремахва форматирането на стила от HTML страницата.
4.2. История
През първите пет години (1990 – 1995 г.) HTML премива през редица ревизии и преживява редица разширения – път към по-прагматичен подход, известен като HTML 3.2, който е завършен през 1997 г. HTML 4.01 се появява по-късно същата година. Година след това се работи по еквивалентен на XML еквивалент, наречен XHTML. Това усилие започва с преформатирането на HTML 4.01 в XML, известен като XHTML 1.0. И така до днешния HTML5.
4.3. DOM HTML
Тази спецификация дефинира абстрактен език за описване на документи и приложения и някои приложни програмни интерфейси (API), които взаимодействат с представяния в паметта на ресурси, които използват този език.
Представянето в паметта е известно като "DOM HTML" или "DOM" за кратко.
Има различни конкретни синтаксиси, които могат да се използват за предаване на ресурси, които използват този абстрактен език, два от които са дефинирани в тази спецификация.
Първият такъв конкретен синтаксис е HTML синтаксиса. Това е форматът, предложен за повечето автори. Той е съвместим с повечето наследствени уеб браузъри. Ако даден документ се предава с типа text/ html, той ще бъде обработен като HTML документ от уеб браузъри. Тази спецификация дефинира най-новата версия на HTML синтаксиса, познат просто като "HTML".
Вторият конкретен синтаксис е XHTML синтаксисът, който е приложение на XML. Когато даден документ се предава с типа XML, като например application/xhtml + xml, той се обработва като XML документ от уеб браузъри, който се анализира от XML процесор. Обработката за XML и HTML се различава; по-специално, дори и незначителни синтактични грешки ще попречат на документ, означен като XML, да бъде напълно изобразен, докато те ще бъдат игнорирани в HTML синтаксиса. Тази спецификация определя последната версия на XHTML синтаксиса, известен просто като "XHTML".
4.4. HTML елементи
HTML също така определя специални елементи за дефиниране на текст със специален смисъл.
HTML използва елементи като <strong> и <em> за форматиране на изход, като удебелен (получер) или курсивен текст.
<strong> – Important text
Елементът HTML
<strong> дефинира текст с добавена семантична „силна“ важност.
<em> – Emphasized text
Елементът HTML
<em> дефинира подчертания текст с добавена семантична значимост.
<mark> – Marked text
Елементът HTML
<mark> дефинира маркиран или подчертан текст.
<small> – Small text
Елементът HTML <small> дефинира по-малък текст.
<del> – Deleted text
Елементът HTML <del> дефинира изтрития (премахнат) текст.
<ins> – Inserted text
Елементът HTML <ins> дефинира вмъквания (добавен) текст.
<sub> – Subscript text
Елементът HTML <sub> дефинира абонирания текст.
<sup> – Superscript text
Елементът HTML <sup> дефинира надписания текст.
Глава 5. JavaScript

5.1.Значение
JavaScript е езикът за програмиране на HTML и уеб. JavaScript може да променя HTML съдържание. Един от многото методите на JavaScript JavaScript е getElementById (). В HTML JavaScript кодът трябва да бъде вмъкнат между маркерите <script> и </ script>. Могат да се поставят произволен брой скриптове в HTML документ.
<script type="text/javascript">
$(window).load(function(){
$('#myModal').modal('show');
});
</script>
</xsl:template>
Поставянето на скриптове във външни файлове има някои предимства:
- Това прави HTML и JavaScript по-лесни за четене и поддръжка
- Кешираните JavaScript файлове могат да ускорят зареждането на страници.
- Външните скриптове могат да се посочват с пълен URL адрес или с пътека спрямо текущата уеб страница.
Скриптовете могат да бъдат поставени в <body> или в секцията <head> на HTML страница или и в двете.
<head>
<body>
Много от нашите компоненти изискват използването на JavaScript за работа. По-конкретно, те изискват jQuery, Popper.js и нашите собствени приставки за JavaScript.
Компоненти, изискващи JavaScript са:
- Сигнали за отхвърляне;
- Бутони за превключване на състояния и функционалност за отметка / радио;
- Плъзгащи се поведения, контроли и индикатори;
- Свиване за превключване на видимостта на съдържанието;
- Падащи менюта за показване и позициониране (също изисква Popper.js);
- Модули за показване, позициониране и превъртане;
- Navbar за разширяване на плъгина ни за свиване, за да се приложи реагиращо поведение;
- Инструменти и popovers за показване и позициониране (също изисква Popper.js);
- Scrollspy за поведението на превъртане и актуализациите за навигация;
Синтаксисът в JavaScript е набор от правила, как се изграждат програмите му. Той дефинира два типа стойности:
Фиксирани стойности и стойности на променливи. Фиксираните стойности се наричат буквални. Променливите стойности се наричат променливи. Те трябва да бъдат идентифицирани с уникални имена. Тези уникални имена се наричат идентификатори.
Общите правила за създаване на имена на променливи (уникални идентификатори) са:
- Имената могат да съдържат букви, цифри, долни черти и знаци за долар;
- Имена трябва да започват с буквен знак;
- Имената също могат да започват с $ и _ ;
- Имената са чувствителни към буквите (y и Y са различни променливи);
- Запазените думи (като JavaScript ключови думи) не могат да се използват като имена;
Най-важните правила за писане на фиксирани стойности са:
Числата са написани със или без десетични знаци: 15 или 15.05
Strings (низове)са части от текст, написан в двойни или единични кавички: "Text" или 'Text'.
Използват се променливи за съхраняване на стойностите на данните.
JavaScript използва ключовата дума var за деклариране на променливи. За изчисляване на стойностите се използват аритметични оператори (+ - * /).
Коментарите в JavaScript могат да се използват и за предотвратяване на изпълнението при тестване на алтернативен код, както и за обясняване на кода на JavaScript и за по-лесно четене. Аритметичните оператори се използват за извършване на аритметични числа:
+ Addition (допълнение)
- Subtraction (изваждане)
* Multiplication (умножение)
/ Division (деление)
% Modulus (Remainder) (деление с остатък)
++ Increment (увеличение)
-- Decrement (снижаване)
Логически оператори на JavaScript:
&& логически и
|| логически или
! логично не
& – и
| – или
~ – не(или отрицание)
Глава 6. Bootstrap

6.1.Значение
Bootstrap e популярна библиотека от съчетание на HTML структура, CSS форматиране и JavaScript. Тя използва няколко важни глобални стила и настройки, чиято идея е да бъдат съвместими с всички съвременни браузъри и интернет страниците да се изобразяват на всички възможни електронни устройства – от екраните на домашните компютри до най-малките смартфони. Това се постига чрез няколко идеи, най-важната от които е:
Отзивчив мета етикет (Responsive meta tag):
<meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no">
Тъй като Bootstrap е разработен предимно за мобилни устройства – стратегия, при която първо оптимизираме кода за мобилни устройства и след това увеличаваме необходимите компоненти, като използваме CSS медийни заявки. За да се осигури правилното представяне и мащабиране за всички устройства, се добавя по-горната инструкция като поделемент на <head>.
Box-sizing
.selector-for-some-widget { box-sizing: content-box; }
Тази инструкция гарантира, че подложката не оказва влияние върху крайната изчислена ширина на елемента.
Reboot
За подобрено рендериране между браузъри се използва Рестартиране, за да се коригират несъответствията в браузърите и устройствата.
Кодът в следващите редове по-долу е използван за текущата магистърска теза.
<table class="table table-striped">
<tbody><tr><th><abbr title="tei:titleStmt/tei:title">Документ</abbr></th><td>
Ето един пример как би могла да изглежда една таблица:
Глава 7. Как се съчетaват всички технологии в едно?
Един от възможните подходи е да се използва база от данни и уеб сървър, които са интегрирани в едно приложение. За целта бе използвана noSQL XML native база от данни с отворен код, известна като eXist database (http://exist-db.org/). В рамките на приложението бяха използвани всички споменати технологии и решения, като общата инфраструктура би могла да се представи по следния начин:
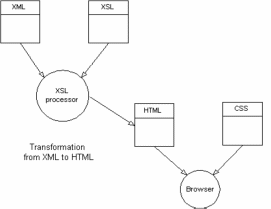
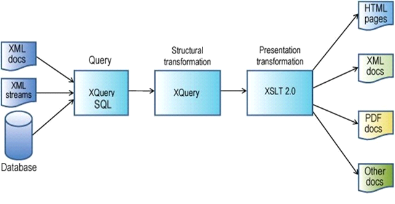
7.1. Няколко подхода
Съществуват различни подходи за работа с XML документи. Единият от тях е чрез трансформация на файла преди обработката в сървърна среда. Другият вариант е всичко да се случва в средата на уеб сървъра за приложения (web application server), който работи с база от данни. И в двата случая е възможно един XML файл да бъде форматиран и представен в различни форми в зависимост от нуждите ни.
В случая е избран вторият подход. При него от можехме да избираме също два варианта – трансформацията да се осъществи с помощта на XSLT или на XQuery с помощта на модулите на Typeswitch (). Бе избран първият от тях. При него XSLT служи за трансформацията на данните, а XQuery при заявки – търсене и екстракция на данни.
Глава 8. eXist database

8.1. Значение. Софтуерната платформа на електронната публикация
Електронната публикация на изданието на Васил Миков е изцяло оформена като приложение на базата от данни eXist (http://exist-db.org).
eXist съчетава в себе си noSQL XML native база от данни, с Java уеб сървър за приложения (по избор Jetty, Tomcat, Resin, Glassfish, Payara, JBoss/Wildfly или някой друг). Приложението може да работи с цялото семейство на XML – XML, XPath, XSLT, XQuery, XForms, XInclude като индексира както чисто текстови, така и бинарни файлове.
Идеята на създателите му е да предоставят платформа, която е способна да публикува и изгражда самостоятелни и богати на възможности уеб приложения. Платформата се разработва от 2001 г. от малък кръг специалисти и почива изцяло на отворен код и най-известните стандарти в областта. Изграждането на приложенията в eXist се извършва изцяло в Интернет среда като за целта има вграден редактор, който в реално време обновява базата от данни.
За индексацията на данните и за общо търсене eXist използва възможностите на Apache Lucene – търсеща програма с отворен код ().
8.2. Инсталация
За инсталация могат да се използват изпълним java архив файл (jar) или формат, разпознаваем от Java уеб сървърите (war). Предварително условие е на компютъра, на който се инсталира, да има работеща среда на Java. За повече информация вж. на Интернет страницата на приложението:
8.3. Интернет публикацията на книгата на В. Миков в средата на eXist
Всяка една публикация в средата на eXist може да се изгради от самото начало, използвайки вградения програмен редактор eXide или да се оформят отделните файлове според определената от приложението архитектура и да се въведат чрез организатора на пакети (Package Manager).
8.4. Структура на директориите и файловете
Нашето приложение (файлове и директории) под eXist изглежда така:
/data
/modules
/pages
/resources
/templates
build.xml
collection.xconf
controller.xql
error-page.html
expath-pkg.xml
pre-install.xql
repo.xml
Централната директория
Файловете в централната директория на приложението служат за неговото инсталиране и конфигуриране.
Файлът build.xml създава т. нар. xar (eXtensible ARchive format) архив – файлът, който се разпознава от редица Java сървърни приложения и служи, като правило за инсталация (вж. напр. XAR). Той взима информацията от другите файлове и създава цялостната йерархия и зависимости, които служат за инсталацията
controller.xql създава пътечките към основните страници и директории в приложението.
error-page.html е страница, която се извиква от сървъра, ако не е намерена страницата, която следва да бъде изобразена.
expath-pkg.xml описва общата информация на приложението и неговите основни зависимости. В случая този кратък файл изглежда така:
<package xmlns="http://expath.org/ns/pkg" name="http://www.slav.uni-sofia.bg/ns/proizhod" abbrev="VMikov-Proizhod" version="1.0" spec="1.0">
<title>Произходъ и значение на имената на нашитѣ градове, села, рѣки, планини и мѣста</title>
<dependency package="http://exist-db.org/apps/shared"/>
</package>
Можем да „преведем“ тази информация по следния начин. Това е приложение с регистрация http://www.slav.uni-sofia.bg/ns/proizhod и кратко име VMikov-Proizhod в своята си първа версия. Името му е Произходъ и значение на имената на нашитѣ градове, села, рѣки, планини и мѣста и то зависи от общите ресурси на системата:
<dependency package="http://exist-db.org/apps/shared"/>
Expath e протокол, предназначен за пакетиране на файлове от системата на XML с цел тяхното последващо инсталиране. Ако XAR e общ формат, предназначен най-вече за сървърни Java приложение, то expath служи само за XML файлове (повече информация вж. на http://expath.org).
pre-install.xql създава различните необходими колекции в базата от данни и връзките между отделните компоненти и общата конфигурация.
repo.xml съдържа всички най-важни данни за нашето приложение. В случая той изглежда така:
<?xml version="1.0" encoding="UTF-8"?>
<meta xmlns="http://exist-db.org/xquery/repo">
<description>Това е интернет приложение за публикация на изданието на Васил Миков</description>
<author>Цветелиана Петкова</author>
<status>alpha</status>
<license>GNU-LGPL</license>
<copyright>true</copyright><type>application</type>
<target>proizhod</target>
<prepare>pre-install.xql</prepare>
<permissions user="admin" password="" group="dba" mode="rw-rw-r--"/>
</meta>
collection.xconf съдържа указания за това кои елементи желаем да конфигурираме специално за нашето приложение. В случая индексът изглежда така:
<index xmlns:tei="http://www.tei-c.org/ns/1.0" xmlns:xs="http://www.w3.org/2001/XMLSchema">
<fulltext default="none" attributes="false"/>
<create qname="tei:term" type="xs:string"/>
<create qname="tei:persName" type="xs:string"/>
<create qname="tei:placeName" type="xs:string"/>
<create qname="tei:rs" type="xs:string"/>
<create qname="@ref" type="xs:string"/>
<lucene>
<text qname="tei:p"/>
</lucene>
</index>
Тук са изброени елементите и атрибутите, чиито стойности или текст желаем специално да търсим, заедно с общото търсене по абзаци на Apache Lucene.
Директория data
Директорията data съдържа съставените от нас файлове. Тя се разделя на няколко поддиректории:
/book – тук е цялостният текст от книгата на В. Миков
/editions – тук текстът е разделен на отделни глави
/indices – тук са файловете listplace.xml и listperson.xml
/meta – тук е част от магистърската теза
Директория templates
В директорията templates са зададени два модела за изобразяване на готовите html файлове. eXist работи като извиква един от двата файла и помества новото съдържание като го вмъква като част основната информация. Метаданните и повторящите се елементи на страницата се взимат от т. нар. template файлове.
В нашия случай имаме два модела. Първият, page.html, отговаря за почти всички страница, докато вторият, datatable.html, е специализиран за изобразяването на информацията във вид на таблици.
Нека разгледаме отделните части на един такъв моделен файл. За целта ще изберем общия вариант, page.html. Подобно на всеки един валиден html документ той се състои от част с метаданни, (елемента head) и основна част (body). В елемента head са зададени основната метаинформация, връзките към JavaScript, CSS файловете и към логото на сайта, т. нар. картинка с формат *.ico, която се показва или в лентата на браузъра, или като част от неговия таб.
Ето извадка от нашия файл с пояснения под всеки ред:
<head><title data-template="config:app-title">App Title</title>
Тук се появява заглавието на приложението.
<meta name="viewport" content="width=device-width, initial-scale=1.0"/>
Този ред служи, за да покаже каква е първоначалната големина изобразената страница (1.0 означава 100% от зададената от браусера конфигурация).
<meta data-template="config:app-meta"/>
Този ред извиква приложението, свързано с метаинформацията.
<link rel="shortcut icon" href="$app-root/resources/img/proizhod.ico"/>
Връзка към картинката.
<link href="$app-root/resources/css/font-awesome.min.css" rel="stylesheet"/>
Връзка към css файла на шрифтовете Fontawesome.
<link rel="stylesheet" type="text/css" href="$app-root/resources/css/cerulean_bootstrap.min.css"/>
Връзка към CSS файла на основната библиотека.
<link rel="stylesheet" type="text/css" href="$app-root/resources/css/style.css"/>
Наши допълнения и уточнения на горната CSS библиотека.
<script type="text/javascript" src="$app-root/resources/js/jquery/jquery-2.2.1.min.js"/>
Зареждане на основната JavaScript библиотека.
<script type="text/javascript" src="$app-root/resources/js/bootstrap.min.js"/>
Зареждане на Java Script библиотеката на Bootstrap.
<link rel="stylesheet" href="../resources/js/scroll-to-top/css/ap-scroll-top.min.css"/>
<script src="../resources/js/scroll-to-top/js/ap-scroll-top.min.js"/>
Връзка към скрипта, който показва стрелка нагоре, за да можем да се върнем в най-горната част на страницата.
<script type="text/javascript" src="$app-root/resources/js/custom.js"/>
Някои допълнителни скриптове.
<link rel="stylesheet" href="../resources/js/cool-share/plugin.css"/>
<script type="text/javascript" src="../resources/js/cool-share/plugin.js"/>
Този скрипт ни позволява да споделяме нашата страница, например във Facebook, Google или Twitter.
</head>
Край на метаданните.
По този начин всяка една страница, извикана от XML формата с помощта на XSLT или XQuery изглежда по еднотипен начин.
Втората част на файла е самото съдържание, като значителна част от кода е посветен на навигацията в горната част на страницата. Идеята е тя да изглежда по абсолютно еднакъв начин навсякъде. Приложеният откъс от код е достатъчно красноречив. Той е пригоден да се разглежда от електронни устройства с всякакъв размер: компютри, лаптопи, таблети и смартфони с различна големина:
<header><nav class="navbar navbar-inverse" role="navigation"><div class="navbar-header">
<button type="button" class="navbar-toggle" data-toggle="collapse" data-target="#navbar-collapse-1">
<span class="sr-only">Toggle navigation</span>
<span class="icon-bar"/><span class="icon-bar"/><span class="icon-bar"/>
</button></div>
<div class="navbar-collapse collapse" id="navbar-collapse-1">
<ul class="nav navbar-nav"><li class="dropdown" id="about">
<a href="index.html" class="dropdown-toggle" data-toggle="dropdown">Начало</a>
<ul class="dropdown-menu"><li><a href="index.html">Начало</a></li>
<li><a href="imprint.html">Издателски данни</a></li></ul></li>
<li class="dropdown" id="toc">
<a href="#" class="dropdown-toggle" data-toggle="dropdown">Изданието</a>
<ul class="dropdown-menu">
<li><a href="showb.html?document=VMikov.xml&directory=book&stylesheet=xmlToHtml">Книгата</a></li>
<li><a href="tocx.html">Главите на книгата по азбучен ред</a></li></ul></li>
<li class="dropdown"><a href="#" class="dropdown-toggle" data-toggle="dropdown">Индекси</a>
<ul class="dropdown-menu"><li><a href="persons.html">Лица</a></li><li><a href="places.html">Места</a></li><li><a href="terms.html">Ключови думи</a></li></ul></li>
<li><a href="show.html?document=about.xml&directory=meta&stylesheet=meta">Магистърска теза</a></li></ul>
<div class="pull-right"><form method="get" action="ft_search.html" class="navbar-form" id="pageform">
<div class="form-group"><div class="input-group">
<input type="text" class="form-control" name="searchexpr" placeholder="Търсене навсякъде" pattern=".{3,}" required="" title="3 characters minimum"/></div>
<button type="submit" class="btn btn-primary fa fa-search"/></div></form></div></div></nav></header>
Основното съдържание се извиква с помощта само на няколко реда:
<section class="main-content"><div id="content" class="container"/>
<span class="socialShare"><!-- The share buttons will be inserted here --></span><div id="loadModal"/></section>
Това е редът <div id="content" class="container"/>. Това съдържание винаги завършва с извикване на скрипта за споделяне (<span class="socialShare">) и при файловете с публикация на текста, с възможността да се появяват при приближаването на мишката при оформените със синьо части с показването на прозорци с допълнителна информация (<div id="loadModal"/>).
Долната част на страницата е оформена с помощта на извикването на три картинки с връзки към сайтовете на Сoфийския университет, TEI и eXist database:
<div class="container">
<div class="row text-center">
<div class="col-md-2"><a href="http://www.uni-sofia.bg/">
<img src="../resources/img/su-head.png" alt="github" width="50%"/></a>
</div>
<div class="col-md-2"><a href="http://www.tei-c.org/"><img src="../resources/img/We-use-TEI.png" alt="We use TEI"/></a></div>
<div class="col-md-2"><a href="http://exist-db.org/" class="navlink" target="_blank"><img src="../resources/img/existdb.png" alt="eXist-db" width="75%"/></a></div></div></div>
За разлика от предишния модел, datatable.html се състои почти изцяло от връзки към CSS и JS файлове:
<link rel="stylesheet" type="text/css" href="https://cdn.datatables.net/v/bs/jszip-2.5.0/dt-1.10.16/b-1.4.2/b-html5-1.4.2/b-print-1.4.2/datatables.min.css"/>
<script type="text/javascript" src="https://cdnjs.cloudflare.com/ajax/libs/pdfmake/0.1.32/pdfmake.min.js"/>
<script type="text/javascript" src="https://cdnjs.cloudflare.com/ajax/libs/pdfmake/0.1.32/vfs_fonts.js"/>
<script type="text/javascript" src="https://cdn.datatables.net/v/bs/jszip-2.5.0/dt-1.10.16/b-1.4.2/b-html5-1.4.2/b-print-1.4.2/datatables.min.js"/>
<script src="$app-root/resources/js/datatables/dataTables.keepConditions.min.js"/>
<div id="datatable"/>
Основната идея на извикването на толкова много файлове е да може да се трансформира информацията в таблицата в различни формати и да може отделните колони да се подреждат допълнително.
Директория resources
Директорията resources се дели на свой ред на няколко директории:
/css: В тази директория са разположени няколко файла – основният CSS (cerulean_bootstrap.min.css), файлът font-awesome.min.css, който позволява вмъкването на малки картинки в страницата и нашият собствен файл style.css. Благодарение на това, че всички технологии са с отворен код, е възможна тяхната безпроблемна интеграция. В случая това означаваше, че е нужно съвсем малко допълнително форматиране на някои части от уеб страниците. Това засягаше главно по-добрата цветова палитра, за да се синхронизира с навигацията, по-добро форматиране на галерията в началната страница. Добавен бе и старобългарски шрифт:
:lang(chu) { font-family:Bukyvede, sans-serif; font-size: 120%;}
/fonts. Тук са разположени: 1) стандартният шрифт на Bootstrap glyphicons; 2) Шрифтовото семейство на Fontawesome и 3) старобългарският шрифт Bukyvede.
/img. Тук са всички картинки и графични елементи.
/js: Това е мястото на различните Java скриптове
/xslt: Последната по азбучен ред, но не и по значение директория съдържа 4 файла, предназначени да трансформират нашите XML документи в HTML. Те са: listperson.xsl, listplace.xsl, meta.xsl и xmlToHtml.xsl.
Първите два отговарят за предоставянето на допълнителна информация за лицата или за местата, meta.xsl преработва XML файла на магистърската теза в HTML документ, а xmlToHtml.xsl съдържа основните указания за всички файлове.
Ще илюстрираме избрания подход с един пример от последния файл, който служи за оформяне на титулната страница, направата на съдържание от отделните заглавия и вмъкването на основната информация от страницата:
>
<div class="panel-body">
Класът panel-body е стандартна функция на Bootstrap.
>
<xsl:choose><xsl:when test="//tei:front">
<xsl:apply-templates select="//tei:titlePage"/>
<xsl:element name="hr"/></xsl:when>
Това е първият вариант на структура на XML файла. Ако той съдържа елемента front извикай елемент titlePage.
<xsl:otherwise>
<h3><xsl:apply-templates select="//tei:div[@type = 'titlePage']"/>
</h3></xsl:otherwise></xsl:choose>
Другият вариант е файлът да съдържа само общи разграничители (div)
<xsl:element name="ul">
<xsl:for-each select="//tei:body//tei:head">
<xsl:element name="li">
<xsl:element name="a">
<xsl:attribute name="href"><xsl:text>#text_</xsl:text>
<xsl:value-of select="."/></xsl:attribute>
<xsl:attribute name="id"><xsl:text>nav_</xsl:text>
<xsl:value-of select="."/></xsl:attribute>
<xsl:value-of select="."/>
</xsl:element></xsl:element></xsl:for-each>
</xsl:element>
С помощта на тази част от отделните подзаглавия на документа се образува съдържание.
<p><xsl:choose><xsl:when test="//tei:div[@type = 'text']">
<xsl:apply-templates select="//tei:div[@type = 'text']"/></xsl:when>
<xsl:when test="//tei:div[@type = 'transcript']"><xsl:apply-templates select="//tei:div[@type = 'transcript']"/>
</xsl:when>
<xsl:otherwise><xsl:apply-templates select="//tei:body"/></xsl:otherwise></xsl:choose></p></div>
Тази част е насочена към трансформацията на различните вариации на основния текст, като основната идея е те да се форматират по сходен начин.
Директория modules
В тази част са най-важните програмни файлове на проекта. Директорията modulesсъдържа три файла, които отговарят за това как желаем да изглежда нашето приложение и каква функционалност да притежава. Тези файлове са:
app.xql – функции, които желаем да притежава нашата електронна публикация са дефинирани тук. Това е мястото, където се задава и по какъв начин желаем да се трансформират нашишите XML файлове в някакъв друг формат, по какъв начин искаме да се осъществи екстракцията на данните и др.
config.xqm – конфигурира общото пространство от имена, т. нар. XML Namespace (в нашия случай ) като поставя във връзка с останалите файлове. Всички файлове на приложението след това се обръщат към тази информация.
view.xql – задава основните характеристики на приложението във връзка с неговото визуализиране в сървърна среда. Това е мястото, където се дефинират какви модели се използват и къде могат да бъдат открити. В случая са важни редовете:
1) import module namespace config="http://www.slav.uni-sofia.bg/ns/proizhod/config" at "config.xqm";
2) import module namespace app="http://www.slav.uni-sofia.bg/ns/proizhod/templates" at "app.xql";
В първия се посочва общата конфигурация с пространството от имена (Namespaces in XML), а във втория – къде да се открият моделите.
Важно ни се струва да обърнем внимание на отделните функции, дефинирани във файла app.xql, доколкото чрез тях отделните HTML предлагат възможностите на системата в цялост.
declare function app:getDocName($node as node()){
let $name := functx:substring-after-last(document-uri(root($node)), '/')
return $name
};
Чрез тази функция се извиква името на файла на документа.
declare function app:hrefToDoc($node as node()){
let $name := functx:substring-after-last($node, '/')
let $href := concat('show.html','?document=', app:getDocName($node))
return $href
};
Това е функцията, която показва трансформирания документ.
declare function app:XMLtoHTML ($node as node(), $model as map (*), $query as xs:string?) {
let $ref := xs:string(request:get-parameter("document", ""))
let $xmlPath := concat(xs:string(request:get-parameter("directory", "editions")), '/')
let $xml := doc(replace(concat($config:app-root,'/data/', $xmlPath, $ref), '/exist/', '/db/'))
let $xslPath := concat(xs:string(request:get-parameter("stylesheet", "xmlToHtml")), '.xsl')
let $xsl := doc(replace(concat($config:app-root,'/resources/xslt/', $xslPath), '/exist/', '/db/'))
let $collection := functx:substring-after-last(util:collection-name($xml), '/')
let $params :=
<parameters>
<param name="app-name" value="{$config:app-name}"/>
<param name="collection-name" value="{$collection}"/>
{for $p in request:get-parameter-names()
let $val := request:get-parameter($p,())
return
<param name="{$p}" value="{$val}"/>
}
</parameters>
return
transform:transform($xml, $xsl, $params)
};
Това е функцията, която извиква XML файла, свързва го трансформационния скрипт (XSLT) и го показва като HTML. Тук отделните части дефинират колекцията от документи, техните пътеки на сървъра, местата на XML и XSLT файловете, проверяват тяхната валидност и наличие, след което връщат така обработения файл.
Чрез XQuery се създава автоматично съдържание, като се взимат заглавията на всички документи в директорията editions. Това става с помощта на функцията app:toc:
declare function app:toc($node as node(), $model as map(*)) {
for $doc in (collection(concat($config:app-root, '/data/editions'))//tei:TEI)
let $collection := functx:substring-after-last(util:collection-name($doc), '/')
let $title := $doc//tei:titleStmt/tei:title[1]
let $keywords := string-join($doc//tei:keywords/tei:term, ' | ')
let $sortKey := $title
order by $sortKey
return
<tr>
<td>
<a href="{app:hrefToDoc($doc)}">{$title//text()}</a>
</td>
<td>
{$keywords}
</td>
</tr>
};
Този пасаж трябва да се чете така: за документите, които са в колекцията editions с коренен елемент TEI, с възможно съдържание на ключови думи и със сортиране според заглавието, подреди по заглавие, като създадеш таблица с две колони – в първата направи линк към документа чрез неговото заглавие, а във втората помести срещаните ключови думи.
Общото търсене се осъществява с помощта на функцията app:ft_search.
declare function app:ft_search($node as node(), $model as map (*)) {
if (request:get-parameter("searchexpr", "") !="") then
let $searchterm as xs:string:= request:get-parameter("searchexpr", "")
for $hit in collection(concat($config:app-root, '/data/editions/'))//*[.//tei:p[ft:query(.,$searchterm)]|.//tei:cell[ft:query(.,$searchterm)]]
let $href := concat(app:hrefToDoc($hit), "&searchexpr=", $searchterm)
let $score as xs:float := ft:score($hit)
order by $score descending
return
<tr>
<td class="KWIC">{kwic:summarize($hit, <config width="40" link="{$href}" />)}</td>
<td><a href="{$href}">{app:getDocName($hit)}</a></td>
</tr>
else
<div>Нищо не е намерено</div>
};
Идеята тук е търсенето да се осъществява в директорията editions, при намирането на резултат да се дава контекст, като намереното съчетание се изобразява по средата и е свързано със съответния текст, а също така да се даде информация за количеството случаи в съответния файл.
Списъкът с местата се извиква с функцията app:listPlace. Тя обслужва два типа информация. Едната е свързана с четенето на съответната част от книгата и при приближаването на мишката се показва екран с допълнителна информация, а от друга страна цялата информация за съответното място се получава от файла listplace.xml. Кодът е следният:
declare function app:listPlace($node as node(), $model as map(*)) {
let $hitHtml := "hits.html?searchkey="
for $place in doc($app:placeIndex)//tei:listPlace/tei:place
let $nametype := $place/@type
let $placeName := $place/tei:placeName
let $region := $place/tei:region
let $suffix := $placeName/@ana>
let $lat := tokenize($place//tei:geo/text(), ' ')[1]
let $lng := tokenize($place//tei:geo/text(), ' ')[2]
let $idno := $place//tei:idno[1]
let $normdata := if($idno) then <a href="{$idno}">{$idno}</a> else '-'
return
<tr>
<td>
<a href="{concat($hitHtml, data($place/@xml:id))}">{$place/tei:placeName[1]}</a>
<br/> {$region}
</td>
<td>{for $altName in $place//tei:placeName return <li>{$altName}</li>}</td>
<td>{data($nametype)}</td>
<td>{data($suffix)}</td>
<td>{$normdata}</td>
<td>{$lat}</td>
<td>{$lng}</td>
</tr>
};
Резултатът е оформен като таблица в няколко колони. В първата е предпочитаното име на мястото заедно с региона, ако има няколко еднакви местни имена, във втората са алтернативни (стари, на други езици или просто с друг правопис) топоними, в третата е типа на топонима (ойконим, ороним, хидроним, хороним и т.н.), четвъртата отпраща към карта в Geonames, a другите дават данни за географската ширина и дължина.
Подобна е идеята и на функцията app:listPers, но тук тя е свързана с имената на лицата:
declare function app:listPers($node as node(), $model as map(*)) {
let $hitHtml := "hits.html?searchkey="
for $person in doc($app:personIndex)//tei:listPerson/tei:person
let $nalis := $person/tei:note/tei:p[3]/text()
let $nalis_link := if ($nalis != "няма посочка към НАБИС") then
<a href="{$nalis}">{$nalis}</a>
else
"-"
return
<tr>
<td>
<a href="{concat($hitHtml,data($person/@xml:id))}">{$person/ tei:persName/tei:surname}</a>
</td>
<td>
{$person/tei:persName/tei:forename}
</td>
<td>{$nalis_link}</td></tr>
};
Тук идеята е да свърже името на изследователя, цитиран от В. Миков с кратки данни за него и връзка към академичния своден каталог НАБИС (http://nalis.bg).
Една от най-важните функции на системата е свързана с начина на синхронизация между стойностите на атрибутите при имената в текста на изданието с тези на списъците с места и имена. Това се осъществява с помощта на следната XQuery функция:
declare function app:indexSearch_hits($node as node(), $model as map(*), $searchkey as xs:string?, $path as xs:string?){
let $indexSerachKey := $searchkey
let $searchkey:= '#'||$searchkey
let $entities := collection($app:editions)//tei:TEI[.//*/@ref=$searchkey]
let $terms := collection($app:editions)//tei:TEI[.//tei:term[./text() eq substring-after($searchkey, '#')]]
for $title in ($entities, $terms)
let $hits := if (count(root($title)//*[@ref=$searchkey]) = 0) then 1 else count(root($title)//*[@ref=$searchkey])
let $snippet :=
for $entity in root($title)//*[@ref=$searchkey]
let $before := $entity/preceding::text()[1]
let $after := $entity/following::text()[1]
return
<p>... {$before} <strong><a href="{concat(app:hrefToDoc($title), "&searchkey=", $indexSerachKey)}"> {$entity/text()}</a></strong> {$after}...<br/></p>
return
<tr><td>{$hits}</td>
<td>{$snippet}<p style="text-align:right">({<a href="{concat(app:hrefToDoc($title), "&searchkey=", $indexSerachKey)}">{app:getDocName($title)}</a>})</p></td></tr>
};
Идеята на функцията е да регистрира всяка поява на съчетанието на атрибут ref, чиято стойност започва с #, независимо от елемента, чиято част е атрибутът. Ако това е вярно, то в списъка с места и лица трябва да съществува стойност на атрибута xml:id (идентификатор на XML елемент), който да има същата стойност, само че без начално #. С други думи, ако в текста имаме <rs type="place" ref="#place_Pleven">Плевенъ</rs>, то във файла lisplace.xml със стойност на елемент Pleven, например <place xml:id="Pleven"> ...</place>. В противен случай връзката между двете няма да бъде осъществена.
Директория pages
В тази директория се съдържат HTML файлове от два типа. Към първият принадлежи началната страница на приложението (index.html) и файлът с информация за издателските данни (imprint.html). Към втория принадлежат файлове, които извикват отделните фунции на приложението. Така например файлът places.html оформя страницата според page.html (вж. по-горе за моделите), създава таблица със седем колони и извиква функцията app:listPlace (вж. по-горе). Заглавките на отделните колони се оформят по следния начин:
<thead>
<tr>
<th class="header">Местни имена</th>
<th>Други имена</th>
<th>Тип на името</th>
<th>Словообразуване</th>
<th>Данни</th>
<th>Lat</th>
<th>Lng</th>
</tr>
</thead>
Това означава, че едната колона, първата, е основната (header). Извикването на функцията е в основното тяло на таблицата:
<tbody id="myTableBody"><tr data-template="app:listPlace"/></tbody>
В края на файла са поместени два JS. Първият позволява да се види или да се вземе информацията от таблицата в различен формат:
var table = $('#myTable').DataTable({
keepConditions: true,
"pageLength": 25,
dom: 'Bfrtip'
});
Смисълът на втория е да се подредят отделните колони и да се търси допълнително в тях:
$(document).ready(function() {
$("#myTableBody").show({});
$('#myTable tfoot th').each( function () {
var title = $(this).text();
$(this).html( '<input type="text"/>' );
});
$("#myTable tfoot").show();
table.columns().every( function () {
var that = this;
$( 'input', this.footer() ).on( 'keyup change', function () {
if ( that.search() !== this.value ) {
that
.search( this.value )
.draw();
}
} );
} );
});
Смисълът на двата скрипта е да съсъщестуват при оформянето на списъците на местата или лицата.
Глава 9. Справочната информация
Съчетаването на отделните части се извършва с помощта на HTML страниците, чрез които в реално време се осъществяват заявки за търсене, постига се екстракция на данни, осъществяват се връзките между отделните части или се трансформират XML файлове. Тъй като цялата информация се съхранява в база от данни, нейната обработка става изключително бързо и резултати са мигновени.
Както казахме в увода, засега в центъра на нашето внимание бе електронното издание, а не лингвистичната информация, която се съдържа в книгата на Васил Миков. Целта ни бе да се съсредоточим върху технологическата част на подобно издание. Все пак, в редица случаи сме допълнили списъка с топоними с полезна информация. Тя е от два вида:
1. Класификация на топонимите. Към всеки от тях е допълнен неговият вид с помощта на международната терминология – ойконим, хороним, ороним, спелеоним, хидроним, урбоним, дромоним, дримоним, каселоним (вж. напр. Вътов 1998: 240–279).
2. Допълнения при словообразуването. При повечето славянски наименования са допълнени начините на словообразуване, главно суфиксите. Това е една от колоните в списъка с топонимите, която позволява чрез написването на отделния суфикс, да се извикат всички случаи с неговата поява в името.
Стори ни се полезно при четенето на книгата да се добави информация за цитираните от В. Миков автори. По този начин читателят се сдобива с данни за известни учени, всеки един от тях с важни изследвания в различни области – филология, история, археология. В бъдеще тези персоналии ще бъдат обогатени с данни за исторически лица, чиито имена се срещат в книгата.
Заключение
Предложеният подход към електронното издание на книгата на Васил Миков „Произход и значение на имената на нашите градове, села, реки, планини и места“ ни се струва уместен при електронното публикуване на научни трудове. Той се опитва да съчетае идеите на традиционното класическо издание в Интернет с използването на всички технологии от семейството на XML и HTML, поместени в една база от данни и управлявани от уеб сървър за приложения.
В рамките на работата се предлага модел за издание и обработка на данните, който е особено подходящ при нужда от редица справки, свързани с четенето на подобен труд. Затова от значение е идеята не просто да се публикува текста и/или снимките от старата книга, а тя да бъде снабдена със справочен апарат във вид на допълнителна информация – в случая списъци с топоними и сведения за авторите, споменати от Васил Миков. Особено полезно ни се струва, че тези списъци могат да играят роля и на самостоятелни приложения, които да се използват и при други издания.
Тази работа е илюстрация как само с използването на продукти с отворен код, придържайки се към международни стандарти, препоръки, спецификации и добри практики, може да се изгради съвременно електронно издание, което да извика за нов живот старата книга и да предизвика връщането към идеите и дискусиите, съдържащи се в нея.
Едно бъдещо прерастване на магистърската теза в научен проект ще ни позволи да допълним информацията, коригираме грешките при поднасянето ѝ, прибавим нови и уточним съществуващите топоними, въведем коментари и изградим допълнителни пътища за поднасяне на лингвистичната информация.
Използвана литература
1. Книги и статии
2. Софтуер, стандарти, препоръки и проекти
Andorfer, Peter. 2017. Die Korrespondenz von Leo von Thun-Hohenstein. Проектът;. Код на приложението: https:// github.com/acdh-oeaw/thun (3.02.2018)
Apache Lucene (3.02.2018)
Bootstrap (Web toolkit – HTML, CSS, JS) (3.02.2018)
Bootswatch (Free themes for Bootstrap): (3.02.2018)
CSS (Cascading Stylesheet Language): (3.02.2018)
DOM (Document Object Model) (3.02.2018)
EBNF (Extended Backus-Naur Form), ISO/IEC 14977 (3.02.2018)
eXist database (XML Native database) (3.02.2018)
EXPath (Standards for Portable XPath extensions) (3.02.2018)
HTML (HyperText Markup Language): (3.02.2018)
Glassfish (Java application server) (3.02.2018)
JavaScript = ECMAScript (European Computer Manufacturers Association) Script
Jboss/Wildfly (Java application server): (3.02.2018)
Jetty (Java application server) (3.02.2018)
JQuery (JavaScript Library) (3.02.2018)
JSON (JavaScript Object Notation) (3.02.2018)
Namespaces in XML (Namespaces in XML 1.0. Third Edition) (5.02.2018)
noSQL database (3.02.2018)
ODMG (Object Data Management Group. Standard for Storing Object) (3.02.2018)
Payara (Java application server) (3.02.2018)
Resin (Java application server) (3.02.2018)
RFC-3629 (UTF-8, a transformation format of ISO 10646) (3.02.2018)
SQL (Structured Query Language): Comparison of different SQL impelentations (02.02.2018)
TEI (Text Encoding Initiative). P5: Guidelines for Electronic Text Encoding and Interchange. Version 3.3.0. Last updated on 31st January 2018, revision f4d8439. (3.02.2018)
Tomcat (Java application server): (3.02.2018)
WAR (Web Application Resource или Web application ARchive) (3.02.2018)
XAR (eXtensible ARchive format) (3.02.2018)
XDM (XQuery and XPath Data Model) (3.02.2018)
XForms (XML Forms) (3.02.2018)
XInclude (XML Inclusions) (3.02.2018)
XLink (XML Linking Language) (3.02.2018)
XML (Extensible Markup Language) (3.02.2018)
XML Namespace (3.02.2018)
XML native database: Staken, Kimbro. 2001. Introduction to Native XML Databases. (02.02.2018)
XML-QL (A Query Language for XML) (3.02.2018)
XQL (XML Query Language) (3.02.2018)
XQuery (XML Query Language) (3.02.2018)
XPath (XML Path Language) (3.02.2018)
XSLT (XSL Transformations) (3.02.2018)